Basic structure
The LALME project was largely carried out before the computer age. It was made using filing slips and paper, pen or pencil. It collected data using the tool traditionally employed by dialectologists, the questionnaire. By 1987 computer technology had progressed to the point where we were able to use computers from the inception of the daughter projects and in a way that is integral to the methodology. Instead of completing questionnaires comprising a set of predetermined 'items', we have developed a method whereby entire texts are transcribed and keyed onto computer disk and are analysed linguistically using programs written in-house. Each word or morpheme in a text is tagged according to its lexical meaning and grammatical function and each newly tagged text is added to the corpus of such texts. Programs then allow information on particular 'items' (defined by one or more tags) to be abstracted from the corpus to identify spatial or temporal distributions of the forms associated with the item.
• A theoretical and methodological Introduction, defining the contents of LAEME, outlining our procedures and theoretical orientation, and defining the contents of the LAEME Corpus of Tagged Texts (CTT)
• the LAEME corpus of lexico-grammatically tagged texts in searchable form in a database
• a searchable database (Index of Sources) containing information about the texts in the LAEME CTT
• a set of Tasks which allow you to search the databases
• a set of explanatory documents:
(a) Text Keys lists the LAEME corpus files by 1. file number; 2. filename; 3. region.
(b) Lexel Specifiers lists and explains the semantic and functional specifiers to the lexical elements of the LAEME tags.
(c) Grammel Commentary lists and explains the grammatical elements of the LAEME tags. This document is designed also for CoNE users (see below).
Linked to LAEME is a Corpus of Narrative Etymologies (CoNE), which aims to provide a narrative etymology for every form type in the LAEME CTT, along with a Corpus of Changes, which explicates the phonological, morphological and orthographic changes invoked in CoNE.
Output may be produced in different formats including concordances, text dictionaries (linguistic profiles), time charts and maps. The tagged corpora provide a detailed lexical-grammatical taxonomy that is useful not just for dialect mapping, but also for the historical study of phonology, morphology, syntax or semantics. The implementation of the corpus approach to linguistic analysis makes feasible a dynamic, interactive concept of dialect atlas.
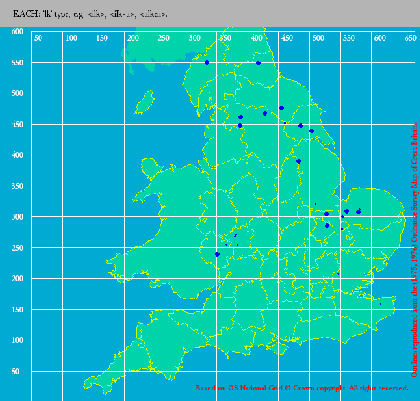
Figure 1. Map item EACH showing features ‘lk’ type, e.g. <ilk>, <ilk-a>, <alken> (1150-1325).
|
