Tagging
(Source: Introduction to A Linguistic Atlas of Early Middle English, ch. 4, http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap4.pdf)
The theory of tags
This atlas is based on a corpus of ‘lexico-grammatically tagged’ texts. It is necessary to define these terms: ‘lexico-grammatically’ may be unfamiliar, and ‘tagged’ has a number of possible interpretations. There are many styles of tagging, with different theoretical bases. Tagging is a taxonomic procedure, defining order and structure within the domain of texts. The tagged texts in LAEME primarily constitute a database for an atlas; they are also a quarry for other forms of linguistic study, e.g. orthographical, phonological, morphological and syntactic. But their primary purpose is to establish a taxonomy for grouping ‘items’ (sensu lato words and morphemes) in order to be able to compare and contrast them spatially and temporally.
A tag is a set of coordinates in a multidimensional space. Tags serve as addresses in this space, enabling us to locate analytically tractable objects, so that they can be extracted for processing. The two primary coordinates of tag-space are lexico-semantic identity and grammatical function. Both are themselves complex subspaces. Lexico-semantic and grammatical spaces are, or can be, hierarchical: certain spaces, given the nature of linguistic structure, are bound by definition to be subspaces of others. Thus functional space (containing categories like ‘direct object’) and subcategory space (e.g. ‘past tense’, ‘plural’) are dimensions of part-of-speech space, while subsenses of lexical items (e.g. ‘locative’, ‘temporal’) are dimensions of lexical or semantic space.
As we conceive tag-space, every item has grammatical coordinates, but not every item has lexical coordinates: e.g. pronouns, determiners and inflectional affixes are not given lexical labels, because they can be construed as carrying only grammatical information. In this we follow the common intuition that ‘grammatical’ forms are bound and lexical forms are free; the exceptions are pronouns and determiners, which though in languages like English are free forms, nonetheless carry only prototypically grammatical information, i.e. they code categories like person, number, gender, definiteness, deixis (for discussion see Croft 2003: §7.2.4). Notationally, the most extended tag type consists of a lexical element (‘lexel’) and a grammatical element (‘grammel’). Some tags, as indicated above, may consist of a grammel only, but none of a lexel only. An exemplary lexel/grammel pair would be:
$brother/nOd
where $ marks the beginning of a tag for computational purposes, and / separates the lexel and grammel, n = ‘noun’, O = ‘object’, d = ‘direct’. The lexel contains identifying semantic information (or to put it another way serves as a mnemonic: see below), and the grammel contains part-of-speech information (n ‘noun’), and functional information (n is an internal argument of its clause, serving the function ‘direct object’). A grammel may also indicate scope or operator/operand relations, e.g.
$brother/n<pr
where the argument is in the scope of the operator: pr = ‘preposition’. We define our tagging as ‘lexicogrammatical’, but in cases like this there is some syntactic tagging as well: the formulation above says that $brother is inside a prepositional phrase, in particular that it is governed by a preposition (i.e. is not an adjunct). This indication of ultra-word constituents (here ‘prepositional phrase’) is in a sense epiphenomenal, just as the label cj ‘conjunction’ is intended to mark a word but also indicates a clause or phrase boundary. Our tagging does not intend, in the first instance, to mark such higher-order constituents (though subsequent user-defined tagging at different levels may do so). [1] The reason for marking operator/operand relations in cases like prepositional phrases is to facilitate recovery of information that may be of historical and/or regional significance. For instance, prepositional objects in early Middle English may be case-coded, and this is of historical and comparative interest. Similarly, at least in early texts, subordinate clauses may have different word-order properties from main clauses, and the grammel ‘cj’ serves as a flag for isolating such clauses for analysis.
A typical example of a grammel-only tag would be
$/P12N
which marks forms of ‘thou’ in subject position, where P = ‘personal pronoun’, 1 = ‘singular’, 2 = ‘second person’, N = ‘nominative’.
The status of tag elements
A tag is a theoretically heterogeneous object. The nonce-terms lexel and grammel have been invented deliberately, to avoid the potential theoretical baggage (as well as definitional specificity) carried by terms like ‘lexeme’, ‘lexical morpheme’ and ‘grammatical morpheme’. Our terminology is designed not to belong to any particular theoretical tradition, but to be compatible with whatever tradition(s) any user happens to work in or be familiar with. Lexels and grammels have different theoretical status. A lexel is in principle an atheoretical taxonomic convenience, merely a name given to an item. It is a language-specific mnemonic or identifier, and the choice of lexel does not attempt to characterise the structure of the lexicon. A lexel therefore makes no ontological assertions. [2] In contrast, a grammel is ‘real’, in that a label like ‘n’ or ‘pr’ represents an object ‘presumed to exist’ within the structure of a language, and to be independently recognisable by outside observers. It makes a potentially realist claim about grammatical structure, within the ambit of a universalist (if limited) theory of grammar. We assume that ‘preposition’ or ‘noun’ or ‘conjunction’ are labels for objects that have non-arbitrary definitions within the universe of grammatical description. The labels are not text-specific: they are not restricted to any regional or temporal provenance. There is also, however, an element of projectible realism for at least some lexels. One would like to be able to ask questions like ‘what is the word for concept X in some other corpus?’. For instance, while $brother is intended merely as an identifier for a set of forms in our corpus, we would assume (a) that it would be related to another lexel — $sister, and (b) that any corpus we worked with would potentially have concepts that might be similarly identified.
Here is a characteristic listing of the forms (in upper case) associated with a tag, though in this example only the lexel is at issue:
$self/aj SELF, SELUE, SELUEN, SELUIN, SEOLF, SEOLFE, SEOLUE, SILF, SOLF, SUELF, SUF, SULF, SULFE
Such a display would suggest at first that the concept ‘lexel’ is really equivalent to ‘lexeme’; but this is not the case, even if in many instances they overlap. Consider, for instance, the main form-types [3] associated with another tag:
$until/cj AL-FORT, AL-HwAT, AyAT, BITUIX-AND, BITUIX-AND-TIL, FORT, FOR-TO, FORTO-yAT, FOR-y~, FORd-y~, SO-yAT, SO-LONGE-yAT, TIL, TIL-yAT, TO, yAT
We would certainly not want to call these ‘word forms of the same lexeme’ (or for that matter ‘allomorphs of the same morpheme’). Historically and synchronically they simply represent different forms that were usable for the same semantic content. This is what we mean by characterising a lexel as a mnemonic rather than as a linguistic element. Lexels therefore may be of a number of different types, some dependent on historical contingencies, others on the linguistic level at which the tagger chooses to work. The tagger’s choice may be dependent on possible regional differences in the expression of the same semantic content. This for example explains the heterogeneity of forms under the semantic lexel $until above.
4.3. Typology of lexels
LAEME lexels are drawn from six different linguistic sources:
1. Modern English
2. Old English
3. Old Scandinavian
4. Middle English
5. Composite
The first recourse for choice of lexel is a Modern English identifier. This may be either a descendant or semantic equivalent of the Middle English form being tagged (e.g. $brother). Type 1 also includes combinations of Modern English identifiers that may not in fact be Modern English words in those combinations but whose elements are all Modern English (e.g. $unkinness ‘unnaturalness’).
In some cases there is no Modern English equivalent for our Middle English forms (e.g. flēmen ‘put to flight’, fraisten ‘inquire’). In these cases, we use approximate etyma as identifying labels, e.g. Old English $fle:man or Old Scandinavian $freista. We also utilise Old English or Old Scandinavian labels where the apparent Modern English equivalent would be ambiguous in a Middle English context. For example ModE ‘lie’, like ME līen, conflates two historically different words with different meanings: OE lēogan ‘tell a lie’ and OE licgan ‘lie down’. We therefore use the lexels $le:ogan and $licgan respectively. [4] The Old English labels are normally in the West Saxon shape familiar from the standard dictionaries and grammars, even if these are not directly ancestral to any forms in the corpus. For instance, we sometimes use early West Saxon identifiers such as $cierran and $di:egel even though early West Saxon is not ancestral to late West Saxon, and late West Saxon itself is ancestral to only a small proportion of our corpus forms. Except where otherwise indicated, the Old Scandinavian labels (e.g. $-leikr ‘state’) are taken from comparable normalised Old Icelandic forms. [5]
If a word of non-Scandinavian origin has no recorded or naturally reconstructable Old English form, and there is no unambiguous Modern English descendant, we use a Middle English identifier. This category includes loanwords from French, Middle Low German etc. Many of the identifiers in category 4 above will in fact be French loan words, but choosing one particular French etymon is often problematic given the range of both Anglo-French [6] and Middle English spellings. In most of these cases therefore the MED headword has been chosen as the lexel. Relevant etymological information will always be accessible in the Corpus of Etymologies.
Sometimes a lexel will be a composite label e.g. $Ya:that, [7] which has an Old English element and a Modern English element. This is to facilitate comparison of each element with its equivalent simplex lexel.
Annotations to a lexel placed within braces before / and the following grammel refer to some semantic or functional distinction from otherwise identical unannotated or differently annotated lexels. For instance, $before{p}, $before{t} identify the lexel components of the tags $before/pr or $before/av (‘adverb’) when referring respectively to ‘place’ and ‘time’. Similarly, $be:am{l}and $be:am{t}refer respectively to reflexes of OE bēam meaning ‘beam of light’ and ‘tree, timber’. {*} indicates that the lexel label is an unattested word but is assumed to have been the origin of the forms it identifies, e.g. $gri:san{*} ‘terrify’, attested in Old English only with the prefix a-.
Separate lexels are given to prefixes, signalled as such by a trailing hyphen (e.g. $be-, $ge-, $un-), and to derivational suffixes, signalled as such by a leading hyphen (e.g. $-dom, $-hood, $-ly). [8]
4.4 Grammels
The taxa invoked in the grammels are deliberately retrogressive. Our categories are ones that should be accessible regardless of a user’s theoretical orientation. They are deliberately ‘shallow’, i.e. they do not depend on potentially controversial hierarchical structure or on any theory of the binarity or otherwise of syntactic constituents. The tagging is lexico-grammatical in a purely surface sense: it taxonomises lexemes or grammatical items in their linear deployment. In the case of discontinuous structures, such as correlated negations, we also mark the co-membership in constructions of items split on the surface (see §§ 4.4.2.3, 4.4.5.1 and 4.4.6.3 below).
The taxonomic categories are essentially those of ‘traditional’ (Latinate) grammar. Almost all the categories defining the grammels (‘noun’, ‘object’, ‘conjunction’, ‘person’, ‘gender’) will be familiar to linguists or to any user with a modicum of traditional grammatical training. Conceptually we do not go much beyond the taxonomies utilised in 18th-century grammars: few of our taggings would be opaque to Bishop Lowth or Lindley Murray.
A grammel consists of everything in a tag appearing between / and _ , where / divides lexel from grammel and _ precedes a text form. In other words it is a complete grammatical characterisation of a form labelled by a particular lexel. Prefixes and derivational suffixes have grammels beginning /xp and /xs respectively followed by a specifier, indicating what part of speech they are affixed to. [9]
Links
Key to the Grammels [.pdf]
Key to the Lexels and to the Grammels that alone define lexemes [.pdf]
Tag Key: Thorn [.pdf]
Notes
[1] For examples of higher order tagging see Meurman-Solin (2004).
[2] Lexels, however, may sometimes be theoretically heterogeneous. An example would be $in{t}/ 'temporal', $in{p}/ 'place', where the braced label is, because of its universalist reference, distinctly grammel-like.
[3] LAEME formatting conventions reserve lower case letters for ‘special’ characters. Here lower case <w> stands for wynn (ƿ), <y> for thorn (þ), <d> for edh (ð), <yx> for barred thorn (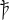 ) = ‘that’. ) = ‘that’.
[4] In LAEME format, length, regardless of standard representational
conventions, is always marked by a following colon.
[5] The actual etymologies may be found in the Etymological Corpus entry
for the lexel in question.
[6] We assume by default that all French loanwords in our corpus will have
been borrowed through the intermediary of some form of French used in
England. For arguments justifying such a position see Rothwell (1998).
[7] The system for indicating Old English characters in the lexels is the
opposite of that used in the cited forms i.e. upper case D, Y, indicate
edh, thorn where lower case indicates these letters in the citations.
[8] These elements are also treated in the Corpus of Etymologies under the
word from which they are derived, e.g. $-dom s.v. $doom/n.
[9] Note that the reflexes of OE ge-, where they survive in verbs, are further specified for context, e.g. as to whether the prefix survives in past participle, infinitive, present tense, etc. The survival of reflexes of OE ge- is of potential semantic interest, as well as being a function of history and regional provenance. By early Middle English the prefix ge- in verbs appears to carry no semantic content differentiating the meaning of verbs with the prefix from those without. For this reason, the lexels for verbs that appear with surviving variants of the prefix are the same as those without.
References
Croft, W. 2003. Typology and universals. Cambridge: Cambridge University Press.
Meurman-Solin, A. 2004. Towards a variationist typology of clausal connectives: methodological considerations based on the Corpus of Scottish Correspondence. In Dossena, M. and Lass, R. (eds.) Methods and Data in English Historical Dialectology. Bern: Peter Lang. 171–198.
Rothwell, W. 1998. Arrivals and departures: the adoption of French terminology into Middle English, English Studies 79: 144–165. See also http://www.anglonorman.net/articles/arrivals.xml.
|
