
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Turo Hiltunen, University of Helsinki
Joe McVeigh, University of Jyväskylä
Tanja Säily, University of Helsinki
For decades, corpus linguists have dealt with large corpora, but the dramatic increase of textual data available in a machine-readable format is rapidly changing the ways of doing research. The proliferation of increasingly large data sets is welcome, as they enable the empirical study of rare phenomena and the analysis of more specialized research questions, among other things. These data sets have also led to an increased collaboration between linguists and scholars in other text-based humanities subjects such as history, under the umbrella term digital humanities. But these new resources also pose new challenges to corpus linguistics, which has typically relied on corpora that are balanced and carefully sampled. If we no longer have full control over what texts are included in our data, it may be difficult to decide what we can do with the findings obtained from it.
This volume discusses the issue of turning data into evidence for claims about language, texts and culture. The collection arose from selected papers read at the From Data to Evidence conference in Helsinki in October 2015. In what follows, we provide a brief overview of some major issues involved in this process in two types of data, commonly referred to as “big data” and “rich data” respectively, and consider their implications for corpus linguistics in particular. The relationship between data and evidence is taken up in the ten contributions included in the volume, which collectively address the issue from a variety of perspectives, using different types of data ranging from existing corpora to newly created resources of varying size and characteristics. The range of methods applied is likewise broad, including both traditional analyses of frequencies and co-occurrence patterns and interactive methods for data-driven exploration of the data.
Profound changes are currently taking place in science and scholarship, mostly brought about by the increasing availability of large data sets (Cukier & Mayer-Schoenberg 2013). In many fields, previous findings and existing theories are called into question by new analyses. This “data explosion” is also influencing linguistics and language studies. Writing for the Guardian in 2014, Mark Liberman lauds large archives of text and speech as “the modern equivalent of the 17th century invention of the telescope and microscope” (Liberman 2014). The potential advantages of big data for linguists are obvious: they enable the study of rare linguistic phenomena, which do not occur in sufficient numbers in small corpora, and allow a wide range of approaches (Davies forthcoming).
What do we talk about when we talk about “big data” in the field of corpus linguistics? One defining characteristic is obviously size, but scholars do not necessarily agree on how big is big enough. Released in 1964, the Brown Corpus already contained one million words of text, and multi-million-word corpora have been available to linguists for decades. Today, few people would consider those early corpora to represent “big data” in the modern sense of the term, however. But is the same true of the 100-million-word British National Corpus (BNC 1993) – does it constitute “big data”, or should that term be reserved for genuinely large corpora, which typically consist entirely of web text? At the same time, it is clear that the size of the corpus alone does not determine its usefulness, and in many areas of linguistics reasonably small corpora have proven extremely valuable. This is particularly true of spoken corpora, historical corpora and specialized corpora, where the scarcity of primary data or the resources needed for collecting and processing it may preclude the compilation of truly large data sets. But a modestly large corpus may still be valuable, and a better measure of its usefulness is often representativeness, which in turn is dependent on the research question (Biber 1993).
While it may not be necessary to put a specific number on what big data means in the context of corpus linguistics, we can certainly list many good candidates. The TenTen family of corpora (Jakubíček et al. 2013) is available in multiple languages, and the currently available English version, the EnTenTen corpus contains 19 billion words (see also Kilgarriff 2012). The ENCOW corpus (Schäfer 2015) contains 16 billion words. Mark Davies has compiled a number of large corpora of English, available through a web interface and as an offline copy. These include the News on the Web corpus (NOW), which contains data from web-based newspapers and magazines and is updated daily; the current size is close to 5 billion words (18 August 2017). The Corpus of Global Web-Based English (GloWbE; Davies & Fuchs 2015) enables comparisons across varieties of English from 20 different countries. With 520 million words, the Corpus of Contemporary American English (COCA; Davies 2008) is considerably smaller, but provides a balanced sample of 5 registers (Fiction, Speech, Academic, Newspaper, Magazines).
Many huge databases of historical documents are also available as plain text and can be analysed using corpus-based methods. These include EEBO-TCP, ECCO-TCP and British Library Newspapers. Under the same heading we could also include the various Wikipedia corpora, such as the 1-billion word Westbury Lab Wikipedia Corpus and Mark Davies’s Wikipedia Corpus (2014), which contains 1.9 billion words. Despite the potential usefulness of these archives to language study, they also raise several issues that need to be considered. Some linguists (e.g. Sinclair 2005) do not regard archives or databases as corpora at all, and it is clear that these collections are incompatible with the traditional sample corpus approach, where the corpus is seen as a maximally balanced and representative collection of the language variety in question.
This issue is also related to the manipulation of data. Indeed, one often-named characteristic of big data is precisely the difficulty of processing data without specialist tools (e.g. Snijders et al. 2012: 1; see also Winters, this volume). This is the main reason why many of these corpora are primarily accessed through a designated web interface, rather than stored locally on a PC. However, native search interfaces are often insufficient, as they typically only offer lists of documents as their output, rather than lists of actual occurrences of words and phrases, which would hold more interest to linguists (McEnery & Hardie 2012: 232). To remedy this situation, new interfaces have been developed that incorporate standard corpus-linguistic functions like concordances and collocations, which increase their usefulness for linguistic research. Examples of such recent developments include the Hansard Corpus, the Old Bailey Corpus and the EEBO Corpus.
What further characterizes most mega-corpora is a certain lack of tidiness, especially compared to carefully balanced corpora, where each text has been chosen according to a set of principles. In the compilation of web corpora, text selection and processing are largely automated. However, as McEnery & Hardie (2012: 7) note, web text is not readily differentiated into categories that would be meaningful to linguists, and that much of it is, as they put it, “casually prepared”. As a result, the users of web corpora have less control over, and information about, what texts are included and what they actually represent; this is potentially a major issue when interpreting the results obtained from these corpora.
In sum, it is clear that we need to look beyond word counts to determine whether a large text collection is of value to us. Another important characteristic is what the corpus enables us to do besides just looking at the texts. This issue is related to the annotation and mark-up available, as well as to what Cukier & Mayer-Schoenberger (2013: 29) refer to as “datafication”: the ability to examine links between different types of quantitative data (e.g. linguistic data and GPS location data; see Coats, this volume). We can refer to corpora including these kinds of features as “rich data”.
Along with big data, the term “rich data” has also become a household phrase in recent years. To the general public, the term is probably best-known through the work of Nate Silver, who became famous by using rich data to correctly predict the presidential election results in 49 of the 50 states in the 2008 United States presidential election (James 2009). For Silver, rich data is “data that’s accurate, precise and subjected to rigorous quality control” (Silver 2015). He illustrates the concepts by using examples from baseball statistics, a field in which the stories of those using rich data have become bestselling books (Lewis 2003) and popular movies. Silver (2015) shows that while big data can tell researchers the scores of every baseball game in history, rich data can give the names of the players, the attendance, “and whether the second baseman wore boxers or briefs” in each game. Rich data, which is sometimes also called “thick” data (see Silvennoinen, this volume), is used to flesh out the big data by giving contextual information for each data point (Marx 2012). In fact, much of the rich data research being done outside linguistics is used for prediction – fans and bettors try to predict who will win a sporting match, medical researchers try to predict where and how diseases will spread, etc. The rich data can add large amounts of information which have previously not been taken into account and lead to better predictions.
For the purposes of corpus linguistics, rich data contains more than just the texts; for instance, it may include metadata on prosody and gestures, or written language conventions, such as spacing and graphical elements. This is further supplemented by analytic and descriptive metadata linked to either entire texts or individual textual elements. There are of course different degrees of richness, and we would argue that what counts as rich data has also changed over time.
In English corpus linguistics, some form of rich data could be said to have been the norm since the beginning. The Brown Corpus of American English (1964) is sampled from multiple different genres, and each sample is associated with hierarchical genre-based metadata (e.g. Informative prose > Press > Reportage). Later on, the corpus was also tagged for parts of speech. The Helsinki Corpus of English Texts (1991), one of the first historical corpora, comes equipped with an extensive parameter coding for each text that includes information on the author, date, dialect, genre, setting, etc. These two corpora have spawned a host of others modelled on similar principles.
Second-generation corpora, such as the Parsed Corpus of Early English Correspondence (2006) and the Corpus of Early English Medical Writing (2005–), provide even more specialized metadata categories and more advanced annotation schemes. We are also beginning to see a third generation that uses TEI XML to encode a number of features, including multimodal ones. Some of these corpora utilize a layered model that provides flexibility and expandability (e.g. Marttila 2014, Brunner et al. this volume).
Nowadays, then, rich data consists of more than genre categories or part-of-speech tagging alongside texts. We would argue that in rich data, richness should be the defining feature – while COCA for instance contains some extra- and intra-linguistic metadata, its primary feature is its large word count relative to older corpora. Naturally, researchers’ opinions on the defining feature of any corpus may vary, and the same corpus can be used in multiple different ways. While we are not able to provide a list of necessary and sufficient features for rich-data corpora, they are typically smaller and more carefully annotated, and some are clearly richer than others. Rich data usually takes more of an effort to produce, although the evolution of technology has enabled researchers to automatically detect or infer certain kinds of metadata in some text types, such as location, gender and age in tweets (cf. Coats, this volume). Furthermore, rich data often involves an element of interpretation: to give a couple of examples, linguistic annotation is always based on theoretical assumptions about language, and in sociolinguistic metadata, while a person’s date of birth may be a more or less plain fact, determining his or her social class may be a much more difficult question.
The advantages of rich-data corpora are manifold. First, they can provide new kinds of evidence about e.g. syntactic, pragmatic and sociolinguistic phenomena. They can also be crucial in triangulating and interpreting the results obtained using big data (Nevalainen 2013, 2015). As the amount and quality of rich data is growing, increasingly user-friendly software is being developed that can better handle the combination of data and certain kinds of metadata. For instance, the upcoming Khepri tool (Mäkelä et al. 2016), which is being developed for historical sociolinguistics, links together corpus texts, social metadata, visualizations and statistical analyses (see Figure 1; see also Siirtola et al. 2016). These improvements allow us to ask not only confirmatory but also exploratory questions.
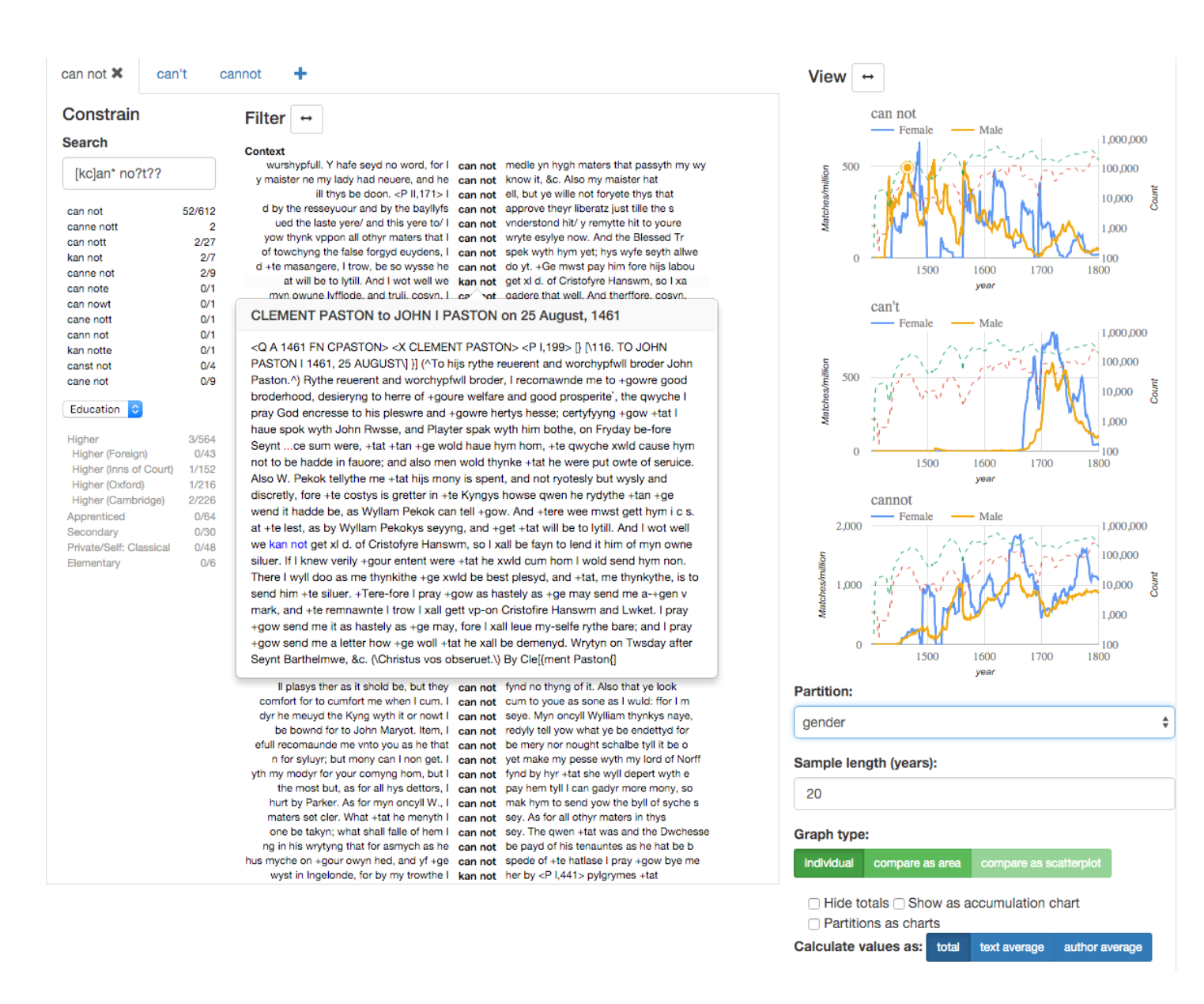
Figure 1. Data exploration in Khepri (Mäkelä et al. 2016).
But rich data also has its disadvantages. As mentioned above, richly annotated corpora are typically small, which limits the scope of studies on them to frequent phenomena (but see Laitinen et al. forthcoming on extracting both big and rich data from Twitter). Moreover, the compilation of rich data sets is far from straightforward: both linguistic annotation and other types of mark-up are laborious and often subjective, and including multiple kinds of annotation and other metadata in a corpus is a complex task for which no cookie-cutter solution exists (see Brunner et al. this volume). [1] It therefore comes as no surprise that querying corpora that include multi-layer metadata can be difficult, and corpus tools that can fluently query and display any of the multiplicity of custom annotation and mark-up systems – or even TEI XML – are still few and far between.
Some work towards standardization has been done, however. The CQPweb interface at Lancaster University, for instance, hosts a number of well-known corpora in an XML format accompanied by an SQL database for metadata, which can be of various kinds (Hardie 2012; see Figure 2). Moreover, Hardie (2014) has proposed a pared-down version of XML encoding called “modest XML” that should provide most of what is needed by a typical corpus compiler, although compilers of more complex rich-data corpora may still need to resort to the more complete but admittedly rather unwieldy TEI encoding; see Marttila (2014) and the DECL project for a TEI-based standard for creating digital editions for corpus linguistics. Continuing Hardie’s work, Rühlemann et al. (2015) promote the use of the generic XML tools XPath and XQuery for corpus linguistics, outlining a “modest” approach to these.
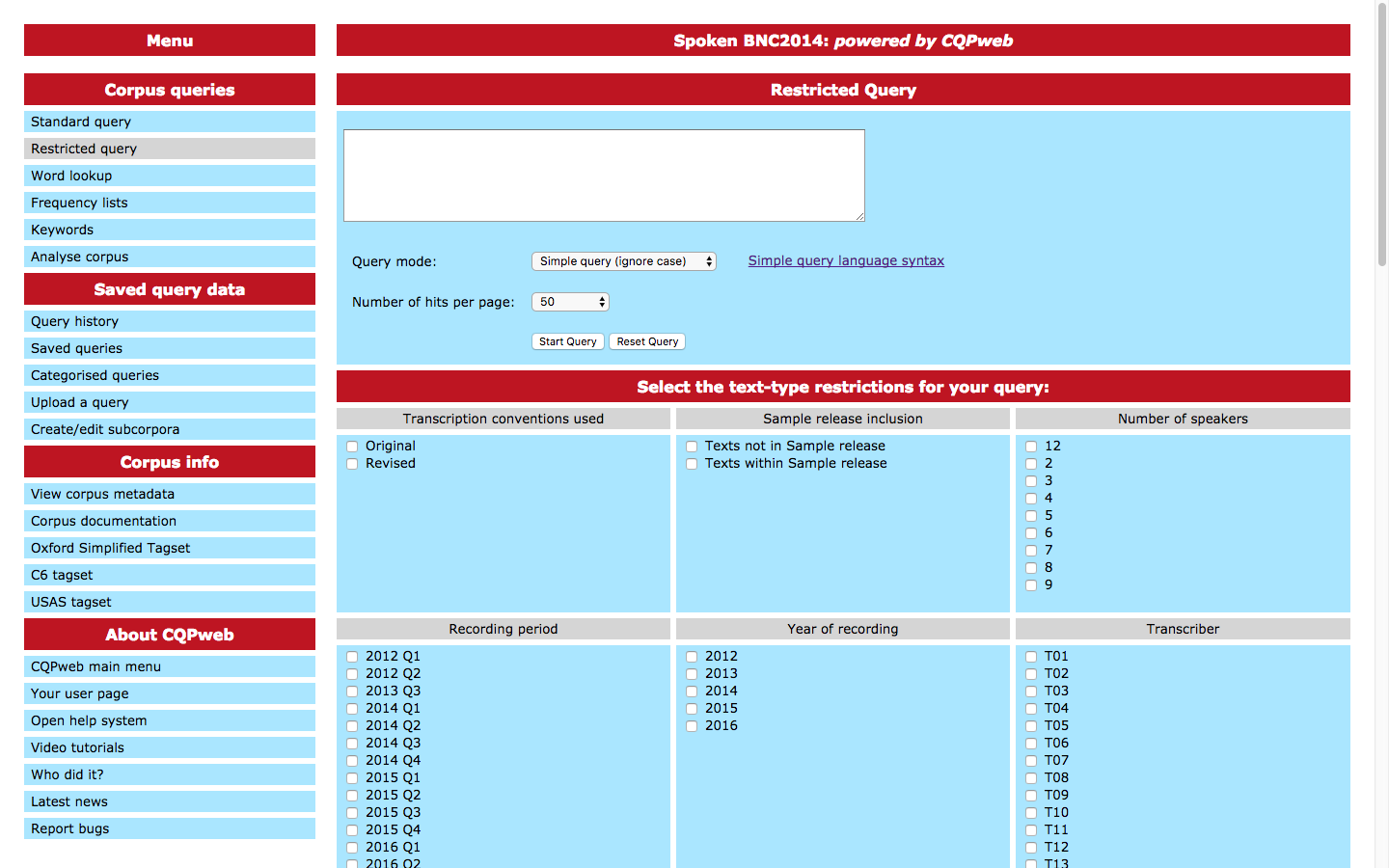
Figure 2. The CQPweb interface, showing some of the metadata query options for the Spoken BNC2014 corpus.
It is difficult to give a clear-cut answer to the question of when the benefits of detailed annotation outweigh the costs of producing it. It is true that results from mega-corpora are more difficult to interpret, and the problems associated with crude, non-linguistic tools based on search engines like Google are well known and documented; according to Kilgarriff (2007), “Googleology is bad science” (see also Davies 2012 and Laitinen & Säily forthcoming). On the other hand, Cukier & Mayer-Schoenberg (2013: 29) argue for a higher tolerance for messiness, because
in an increasing number of situations, a bit of inaccuracy can be tolerated, because the benefits of using vastly more data of variable quality outweigh the costs of using smaller amounts of very exact data.
Moreover, even Kilgarriff’s (2007) well-known statement has recently been challenged by Grieve et al. (2014), who argue that search engine counts can indeed provide useful estimates of rare linguistic phenomena, as long as the focus is on relative, not absolute frequencies. There are, however, specific cases in which easily available big data is simply inadequate. For example, speech is less easily available than written data, especially when the focus is on certain domains (e.g. Brunner et al. this volume). Another example is historical-sociolinguistic research aiming at a wide social coverage, as the lower social ranks rarely produced published writings and their language is therefore not represented in print-based corpora and databases such as Google Books. These and other issues associated with this massive database are addressed in the following section.
Many people outside corpus linguistics became familiar with the use of big data in linguistics in 2011 with the publication of Michel et al.’s (2011) Culturomics paper (Singer 2013). The research described the use of the Google Books (GB) database and an online tool called the Google Ngram Viewer, which allows anyone with internet access to analyse the database. The compilation of the GB database has been accurately described as a “Herculean task” (Davies n.d.). It contains over 15 million books from eight languages (six of which are Indo-European languages). The database also contains metadata on the books, at least in terms of the year of publication. Using this GB database, Michel et al. (2011) created a part-of-speech tagged “corpus” of over 500 billion words (7 languages) from books dating back to the 1500s. Soon other studies using this resource appeared (Kesebir & Kesebir 2012; Perc 2012; Petersen et al. 2012a; Petersen et al. 2012b; Gerlach & Altmann 2013). When scholars began to take a serious look at these papers and the database, however, what emerged seemed to be a new form of armchair linguistics with old problems made digital, rather than what the authors wrote would be “profound consequences for the study of language, lexicography, and grammar” (Michel et al. 2011: 178). The GB corpus is emblematic of many of the problems associated with big and rich data in linguistics.
The first problem involved with the GB corpus (and the studies based on it) is called the “black box” problem (see also Winters, this volume): we do not really know what the corpus contains other than “books”. This label could refer to non-fiction books, fiction books, cook books, medical texts, academic journals or anything else that was entered into the GB database. This is a problem of representativeness, which is what Koplenig (2017: 171) calls “the most fundamental methodological problem in corpus linguistics”. A variation of this black box problem is how researchers cannot know what a computer program does if we only see the output (for a discussion of this problem, see Flanagan, this volume). Obviously, such a problem does not bode well for studies which want to make claims about human culture based on the language in the GB database. The GB team claim awareness of this fundamental problem, but offer only a cryptic explanation for the books in their corpus:
the vast majority of the books from 1800–2000 come from Google’s library partners, and so the composition of the corpus reflects the kind of books that libraries tend to acquire. (Culturomics FAQ; emphasis added)
On top of that, Michel et al. (2011: 176) selected books “on the basis of the quality of their OCR”, i.e. books which were more accurately readable by computers. This threatens to bias the corpus even further (Koplenig 2017). The problem of using a corpus without a bibliography of its contents was raised seven years ago by Jockers (2010), and to date scholars and the public are still in the dark about this crucial information.
The second problem with the GB corpus concerns metadata. Jockers (2013: 121) notes how there is actually a lack of metadata with the GB corpus and says the “only metadata provided are publication dates, and even these are frequently incorrect”. There are also various editions and printings, as well as duplicates of the same work in the GB database. Koplenig (2017) shows how even if the representativeness problem explained above were solved, the metadata problem with the GB corpus prevents researchers from making claims about language and culture using the corpus.
Another problem with the GB database is how its compilers have organized the books into subcorpora. For example, the subcorpus labeled “English fiction” includes not only novels and short stories, but also, according to the creators of the subcorpus, “lots of fiction-associated work, like commentary and criticism” (Culturomics FAQ). Underwood (2011) claims that this means “no humanist will want to rely on the corpus of ‘English fiction’ to make claims about fiction; it represents something new and anomalous”. Linguists who are used to defining fiction in the same way as other humanists (and perhaps society in general) will therefore find this new categorization problematic. It does not render the English fiction subcorpus of the GB corpus unusable, but it certainly makes cross-corpora comparisons impossible.
A final and related problem with the GB database is one of bias. First, Pechenick et al. (2015) have shown that the GB database suffers from an oversampling of scientific texts. This is obviously due to the source of the material in the GB corpus (university libraries) and it is a further reason why claims about language or culture based on the GB database may not be accurate. Second, the GB database does not include any spoken language – an important point that is lost on many researchers and journalists who conflate evidence from the GB database (containing only written language) with evidence about language as a whole (which is of course mostly spoken). Jockers (2013: 122) sums up the problem:
When we talk about the Ngram Viewer as a window into culture, or “culturomics,” we speak only of written culture; even less so, we speak of written culture as it is curated by librarians at major research universities who have partnered with Google in scanning the world’s books.
Obviously, the Michel et al. (2011) paper and the GB database are not the only ones which suffer from these problems. Other studies using big data corpora (sometimes supplemented with the GB database), especially ones done by scholars who are not trained in linguistics, tend to suffer from similar problems. In fact, many of the big data corpora that are available at the moment could be said to have the same problems to a greater or lesser extent. For example, it could be argued that COCA does not include an authentic representation of spoken language because the data is taken from transcripts of television news programs, so the language is not as spontaneous as naturally occurring speech. The questions have been prepared and the transcripts are likely to have been edited. Nevertheless, the GB database is an extreme case which exemplifies the problems listed above. At the moment, researchers using COCA seem to be aware of its limitations and much valuable work has been produced using it (see e.g. Daugs, this volume). Those who have looked into the GB database, however, have mostly found it to be too messy to be of any serious value to linguistic research, even if its sheer size is tempting (e.g. Koplenig 2017, Jockers 2013).
Although they are not without problems, many of the other big data corpora compiled by linguists can offer solutions to the problems posed by the Google Books corpus. For example, COCA is a well-balanced corpus and can arguably be used to answer most questions about the written genres which it contains because it is representative of those genres and the time period from which they come (1990–2015). On the other hand, questions regarding language on social media or websites can be answered using a web crawler or API to compile a specialized big data corpus. These methods of compilation are not only easier than they have ever been, but in the case of social media APIs, for example Twitter’s, they offer the added benefit of coming with metadata, such as location, date, and time (e.g. Huang et al. 2016). The solutions to the problems involved in dealing with big data corpora (such as Google Books) are the same as they have always been. Corpora need to be representative and balanced, not just bigger; bigger is not always better in this regard. If these goals are met, the results and claims made based on the corpora will be valid.
There are many ways of answering the question in the title of this chapter, how to turn data into evidence, depending on the research approach selected. In previous sections, we have discussed some problems related to the analysis of both big and rich linguistic data. The papers in this volume provide various solutions to dealing with such data and to turning it into evidence.
The volume opens with two programmatic papers. Historian Jane Winters discusses what is sometimes forgotten in discussions about big data in the humanities, namely the many inherent problems associated with it. These problems range from the lack of proper tools and metadata to very practical issues in data collecting, such as the unit of analysis and reduplication, and to challenges in interdisciplinary collaboration. Outlining problems in precise detail is important, as it enables us to think about solutions to them. Despite these problems, Winters urges historians and digital humanists to “get to grips” with the available big data sources and get involved in developing methods and tools, as there is great potential for achieving a better understanding of our recent past.
One of the hallmark of science is the reproducibility of results, and this issue is gaining added significance in the context of big and rich data analysis. Reproducibility is also in focus in Joseph Flanagan’s contribution, where he argues that while empirical linguistics is still (and is likely to remain) far away from full reproducibility of research, with currently available tools, it is relatively easy for researchers to allow their readers to reproduce the statistical analysis and the accompanying visualizations. Flanagan outlines a number of strategies and workflows for achieving reproducibility in this specific sense of the term, using the RStudio software environment and online repositories, where raw data and the scripts are made available. His paper, in which the results of an earlier study on genitive variation (Wolk et al. 2013) are reproduced, is also reproducible in its entirety from an accompanying Bitbucket repository.
Three papers in the volume deal with big and rich data in computer-mediated communication (CMC). Marie-Louise Brunner, Stefan Diemer and Selina Schmidt use the Corpus of Academic Spoken English (CASE) to investigate the benefits and challenges posed by rich data in linguistic studies. They note that richly annotated spoken corpora are difficult to work with, and offer some solutions to overcome these difficulties. As the CASE corpus is composed of Skype conversations, there are important decisions to be made when creating the corpus, especially concerning transcription and annotation. The researchers follow established guidelines for spoken corpora and propose using orthographic, part-of-speech-tagged, and pragmatic layers in creating the corpus. Their proposal has implications for other rich data corpora and their discussion offers an overview of the areas of research for which these corpora can best be used.
Steven Coats uses a corpus of English-language Twitter messages from Finland to investigate the different lexical and grammatical features of online communication based on users’ genders. The study looks at the expanding role of English in computer-mediated communication and uses frequency distributions to correlate standard and non-standard lexical features with gender. The features in the corpus created for the article are compared to a corpus of global Twitter messages in English. The study shows how automated rich data can be added to a CMC corpus. The discussion considers previous research on gendered language use, but also shows the interesting way in which sociolinguistic and technological factors, such as the Twitter medium itself, affect the lexical and grammatical features of online Englishes.
From a more applied perspective, Joe McVeigh’s article analyses a corpus of 2,021 subject lines in email marketing messages and compares their linguistic features to other types of CMC and marketing. The study takes into account the metadata of each subject line, including how many emails with each subject line were sent and how many were opened. Research into the CMC sub-genre of email marketing is sparse and McVeigh’s article shows how the linguistic features of email marketing, such as non-standard variations and the use of exclamation points, are not used in the same way as they are in personal and professional email communication. The article offers insight into which linguistic features are more common in successful email marketing campaigns.
The main advantage of large corpora is the amount of data that they provide, and the following two papers make use of large multi-genre corpora to obtain new quantitative evidence for describing linguistic phenomena. Robert Daugs investigates the development of modals and semi-modals in the history of English, using the 400-million-word corpora Corpus of Contemporary American English (COCA) and Corpus of Historical American English (COHA). While diachronic corpus studies on modality are numerous, COCA and COHA are considerably larger than the corpora used in most previous work and thus enable a more detailed analysis of historical changes. While Daugs’s analysis confirms the main trends established previously, it also suggests a number of refinements on the history of individual forms, demonstrating the usefulness of big data in historical corpus linguistics.
Large corpora prove equally useful in the description of English negative-contrastive constructions (e.g. not coffee but tea), which is the topic of Olli Silvennoinen’s paper. While corpora have been used in general descriptions of negation in English, negative-contrastive constructions have not been subjected to detailed corpus study. Using the multi-genre BNC, Silvennoinen shows that much of the variation in the use of this constructions is accounted for by the register: newspaper writing exhibits the various subtypes rather evenly, whereas in conversation asyndetic combinations are dominant. The study also underlines the importance of data that is appropriate, in this case data that is big enough to allow generalisations, and rich (or ‘thick’) enough to enable the identification and analysis of the tokens in their interactional context.
The final three papers of the volume focus on new tools and methods for big and rich data. As one solution to the problem of turning messy big data into evidence (see Section 2 above), Jefrey Lijffijt and Terttu Nevalainen present a simple method of genre classification, demonstrated in the BNC and the Lancaster–Oslo/Bergen Corpus of British English. Using just two features that can be easily retrieved from unannotated corpora – type/token ratio and average word length – the decision-tree based model is able to assign texts to the super-level genres of conversation, fiction, news and academic writing at an accuracy of 80–90%. The accuracy is slightly higher when using another pair of features that does require annotation, namely noun and pronoun ratios. Lijffijt & Nevalainen envision several possible applications for their method: in addition to learning more about big and messy corpora for which no genre metadata is available, the method could be used to assess the stability and comparability of historical corpora, or as an exploratory starting point for studying genre change over time.
Gerold Schneider, Mennatallah El-Assady and Hans Martin Lehmann showcase multiple tools and methods for processing and visualising big data in corpus linguistics, or “workflows from data to evidence”. They address the issue of how to gain insight into large corpora which may require specialist tools as discussed in Section 2 above. Their material of choice is the COHA corpus, to which they have added syntactic parsing. They first focus on user-friendly off-the-shelf tools, after which they move on to more powerful and flexible forms of interactive visualization that can be used to gain an overview of big data, taking topic modeling as an example. Schneider et al. argue that despite the limitations of the methods, such as false assumptions of statistical independence, big data tends to even out any artefacts in the results. Moreover, they show that interactive visualization is a good way of gaining an overview of big data, as it combines the strengths of automatic analysis and human perception.
Another example of the power of human–computer interaction is provided by Tanja Säily and Jukka Suomela, who present an interactive tool for analysing word-frequency differences in corpora. They address one of the key challenges of turning rich data into evidence: creating exploratory tools that enable the user to fluidly move between data and metadata (cf. Section 3 above). The types2 software developed by Suomela is able to incorporate metadata of various kinds, facilitating the analysis and interpretation of rich data. Säily & Suomela demonstrate the use of the tool by exploring variation in the productivity of nominal suffixes in two data sets: conversations in the BNC and personal letters in the 18th-century section of the Corpora of Early English Correspondence, both of which include sociolinguistic metadata. The interactive web pages produced by the tool make it easy to discover and interpret significant differences in word frequencies as well as sparking further hypotheses that can then be tested using the same apparatus. The web pages provide simultaneous access to visualizations, social metadata, the word types in question, as well as the tokens in context. This combination of close and distant reading through linked data is also becoming common in the wider field of the digital humanities (cf. Winters, this volume).
As this brief overview demonstrates, the range of approaches and issues related to data and evidence, as well as to big and rich data, is remarkable. The current interest around the digital humanities is considerable, but we have only seen the beginning stages of this development, and future work will demonstrate what its relationship will be with existing and established areas of study like history, literary and cultural studies, and linguistics. The field of corpus linguistics has already seen a number of recent developments, including the move towards standardized conventions for annotation and mark-up, the increasing use of statistical techniques and advanced visualizations, and the standardized workflows of analysis. That said, we still need to know what our data is like, what the original contexts of production were, and what the corpus is representative of. In other words, the old rules of corpus linguistics still apply.
We would first like to thank the authors for their work in contributing to this volume. We would also like to thank the anonymous reviewers of each chapter (including ours) for offering valuable insights and suggestions of ways to improve the volume.
[1] See also the collections edited by Meurman-Solin & Nurmi (2007) and Meurman-Solin & Tyrkkö (2013), which are devoted to these issues. [Go back up]
British Library Newspapers: http://www.gale.com/c/17th-and-18th-century-burney-newspapers-collection
BNC = British National Corpus. 1993. Distributed by Bodleian Libraries, University of Oxford, on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk
Brown Corpus. 1963–64. Project leaders: W. Nelson Francis and Henry Kučera. http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/
CEEM = Corpus of Early English Medical Writing. 1995–. Project leaders: Irma Taavitsainen and Päivi Pahta. Compilers: Irma Taavitsainen (University of Helsinki), Päivi Pahta (University of Tampere), Martti Mäkinen (University of Stavanger). http://www.helsinki.fi/varieng/CoRD/corpora/CEEM/
COCA = Corpus of Contemporary American English. 2008–. http://corpus.byu.edu/coca/
CQPweb interface at Lancaster University: https://cqpweb.lancs.ac.uk
Culturomics webpage FAQ: http://www.culturomics.org/Resources/faq
Davies, Mark. n.d. “Comparison of COHA, Google Books Standard and Google Books BYU/Advanced”. https://googlebooks.byu.edu/compare-googleBooks.asp
DECL project: https://www.helsinki.fi/en/researchgroups/varieng/digital-editions-for-corpus-linguistics-decl
ECCO-TCP = Eighteenth Century Collections Online – Text Creation Partnership: http://www.textcreationpartnership.org/tcp-ecco/
EEBO Corpus = Early English Books Online Corpus. 2017. https://corpus.byu.edu/eebo/
EEBO-TCP = Early English Books Online ‐ Text Creation Partnership: http://www.textcreationpartnership.org/tcp-eebo/
ENCOW Corpus = English web corpus by COW: http://corporafromtheweb.org/encow16/
EnTenTen Corpus = enTenTen Corpus of the English Web: https://www.sketchengine.co.uk/ententen-english-corpus/
GloWbE = Corpus of Global Web-Based English: https://corpus.byu.edu/glowbe/
Google Books Ngram Viewer: https://books.google.com/ngrams
Google Books Ngram Viewer Info page: https://books.google.com/ngrams/info
Hansard Corpus: https://www.hansard-corpus.org/
The Helsinki Corpus of English Texts. 1991. Compiled by Matti Rissanen (Project leader), Merja Kytö (Project secretary); Leena Kahlas-Tarkka, Matti Kilpiö (Old English); Saara Nevanlinna, Irma Taavitsainen (Middle English); Terttu Nevalainen, Helena Raumolin-Brunberg (Early Modern English). Department of Modern Languages, University of Helsinki. http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/
NOW Corpus = News on the Web Corpus: http://corpus.byu.edu/now/
Old Bailey Corpus: http://www1.uni-giessen.de/oldbaileycorpus/
PCEEC = Parsed Corpus of Early English Correspondence. 2006. Annotated by Ann Taylor, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Compiled by the CEEC Project Team. York: University of York and Helsinki: University of Helsinki. Distributed through the Oxford Text Archive. http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/
Spoken BNC2014: http://corpora.lancs.ac.uk/bnc2014/
TEI XML: http://www.tei-c.org
types2: Type and hapax accumulation curves. 2016. Jukka Suomela. https://users.ics.aalto.fi/suomela/types2/
Westbury Lab Wikipedia Corpus: http://www.psych.ualberta.ca/~westburylab/downloads/westburylab.wikicorp.download.html
Wikipedia Corpus: https://corpus.byu.edu/wiki/
Biber, Douglas. 1993. “Representativeness in corpus design”. Literary and Linguistic Computing 8(4): 243–257. doi:10.1093/llc/8.4.243
Cukier, Kenneth Neil & Victor Mayer-Schoenberg. 2013. “The rise of big data: How it’s changing the way we think about the world”. Foreign Affairs 92(3): 28–40. http://www.jstor.org/stable/23526834
Davies, Mark. 2008–. The Corpus of Contemporary American English (COCA): 520 million words, 1990–present. https://corpus.byu.edu/coca/
Davies, Mark. 2012. “Some methodological issues related to corpus-based investigations of recent syntactic changes in English”. The Oxford Handbook of the History of English (Oxford Handbooks in Linguistics), ed. by Terttu Nevalainen & Elizabeth Closs Traugott, 157–174. Oxford: Oxford University Press.
Davies, Mark. Forthcoming. “Corpus-based studies of lexical and semantic variation: The importance of both corpus size and corpus design”. From Data to Evidence in English Language Research, ed. by Carla Suhr, Terttu Nevalainen & Irma Taavitsainen. Leiden: Brill.
Davies, Mark & Robert Fuchs. 2015. “Expanding horizons in the study of World Englishes with the 1.9 billion word Global Web-based English Corpus (GloWbE)”. English World-Wide 36: 1–28. doi:10.1075/eww.36.1.01dav
Gerlach, Martin & Eduardo G. Altmann. 2013. “Stochastic model for the vocabulary growth in natural languages”. Physical Review X 3(2): 021006. doi:10.1103/PhysRevX.3.021006
Grieve, Jack, Costanza Asnaghi & Tom Ruette. 2014. “Googleology is good science”. Presentation, Workshop on Web Data as a Challenge for Theoretical Linguistics 2014 (WEBTL-2014), Marburg, Germany, March 2014. http://wwwling.arts.kuleuven.be/qlvl/prints/Grieve_Asnaghi_Ruette_2014pres_Googleology_good_science.pdf
Hardie, Andrew. 2012. “CQPweb – combining power, flexibility and usability in a corpus analysis tool”. International Journal of Corpus Linguistics 17(3): 380–409. doi:10.1075/ijcl.17.3.04har
Hardie, Andrew. 2014. “Modest XML for corpora: Not a standard, but a suggestion”. ICAME Journal 38: 73–103. doi:10.2478/icame-2014-0004
Huang, Yuan, Diansheng Guo, Alice Kasakoff & Jack Grieve. 2016. “Understanding U.S. regional linguistic variation with Twitter data analysis”. Computers, Environment and Urban Systems 59: 244–255. doi:10.1016/j.compenvurbsys.2015.12.003
Jakubíček, Milošm, Adam Kilgarriff, Vojtěch Kovář, Pavel Rychlý & Vít Suchomel. 2013. “The TenTen corpus family”. Corpus Linguistics 2013: Abstract Book, ed. by Andrew Hardie & Robbie Love, 125–127. https://www.sketchengine.co.uk/wp-content/uploads/The_TenTen_Corpus_2013.pdf
James, Bill. 2009. “The 2009 TIME 100: Nate Silver”. Time. http://content.time.com/time/specials/packages/article/0,28804,1894410_1893209_1893477,00.html
Jockers, Matthew L. 2010. “Unigrams, and bigrams, and trigrams, oh my”. Matthew L. Jockers. http://www.matthewjockers.net/2010/12/22/unigrams-and-bigrams-and-trigrams-oh-my/
Jockers, Matthew L. 2013. Macroanalysis: Digital Methods and Literary History (Topics in the Digital Humanities). Urbana: University of Illinois Press.
Kesebir, Pelin & Selin Kesebir. 2012. “The cultural salience of moral character and virtue declined in twentieth century America”. Journal of Positive Psychology 7(6): 471–480. doi:10.1080/17439760.2012.715182
Kilgarriff, Adam. 2007. “Googleology is bad science”. Computational Linguistics 33(1): 147–151. doi:10.1162/coli.2007.33.1.147
Kilgarriff, Adam. 2012. “Getting to know your corpus”. Proceedings of the 15th International Conference on Text, Speech and Dialogue (TSD 2012) (Lecture Notes in Artificial Intelligence 7499), ed. by Petr Sojka, Aleš Horák, Ivan Kopeček & Karel Pala, 3–15. Berlin: Springer. doi:10.1007/978-3-642-32790-2_1
Koplenig, Alexander. 2017. “The impact of lacking metadata for the measurement of cultural and linguistic change using the Google Ngram data sets – reconstructing the composition of the German corpus in time of WWII”. Digital Scholarship in the Humanities 32(1): 169–188. doi:10.1093/llc/fqv037
Laitinen, Mikko, Jonas Lundberg, Magnus Levin & Alexander Lakaw. Forthcoming. “Revisiting weak ties: Using present-day social media data in variationist studies”. Exploring Future Paths for Historical Sociolinguistics (Advances in Historical Sociolinguistics 7), ed. by Tanja Säily, Arja Nurmi, Minna Palander-Collin & Anita Auer. Amsterdam: John Benjamins.
Laitinen, Mikko & Tanja Säily. Forthcoming. “Google Books: A shortcut to studying language variability?” Patterns of Change in 18th-Century English: A Sociolinguistic Approach (Advances in Historical Sociolinguistics), ed. by Terttu Nevalainen, Minna Palander-Collin & Tanja Säily. Amsterdam: John Benjamins.
Lewis, Michael. 2003. Moneyball: The Art of Winning an Unfair Game. New York: W. W. Norton & Company.
Liberman, Mark. 2014. “How big data is changing how we study languages”. The Guardian, 7 April 2014. https://www.theguardian.com/education/2014/may/07/what-big-data-tells-about-language
Mäkelä, Eetu, Tanja Säily & Terttu Nevalainen. 2016. “Khepri – a modular view-based tool for exploring (historical sociolinguistic) data”. Digital Humanities 2016: Conference Abstracts, ed. by Maciej Eder & Jan Rybicki, 269–272. Kraków: Jagiellonian University & Pedagogical University. http://dh2016.adho.org/abstracts/226
Marttila, Ville. 2014. Creating Digital Editions for Corpus Linguistics: The Case of Potage Dyvers, a Family of Six Middle English Recipe Collections. Ph.D. dissertation, Department of Modern Languages, University of Helsinki. http://urn.fi/URN:ISBN:978-951-51-0060-3
Marx, Sherry. 2012. “Rich data”. The SAGE Encyclopedia of Qualitative Research Methods. Thousand Oaks, CA: SAGE. doi:10.4135/9781412963909
McEnery, Tony & Andrew Hardie. 2012. Corpus Linguistics: Method, Theory and Practice (Cambridge Textbooks in Linguistics). Cambridge: Cambridge University Press.
Meurman-Solin, Anneli & Arja Nurmi, eds. 2007. Annotating Variation and Change (Studies in Variation, Contacts and Change in English 1). Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/01/
Meurman-Solin, Anneli & Jukka Tyrkkö, eds. 2013. Principles and Practices for the Digital Editing and Annotation of Diachronic Data (Studies in Variation, Contacts and Change in English 14). Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/14/
Michel, Jean-Baptiste, Yuan Kui Shen, Aviva P. Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak & Erez Lieberman Aiden. 2011. “Quantitative analysis of culture using millions of digitized books”. Science 331(6014): 176–182. doi:10.1126/science.1199644
Nevalainen, Terttu. 2013. “English historical corpora in transition: From new tools to legacy corpora?” New Methods in Historical Corpora (Korpuslinguistik und interdisziplinäre Perspektiven auf Sprache 3), ed. by Paul Bennett, Martin Durrell, Silke Scheible & Richard J. Whitt, 37–53. Tübingen: Narr.
Nevalainen, Terttu. 2015. “What are historical sociolinguistics?” Journal of Historical Sociolinguistics 1(2): 243–269. doi:10.1515/jhsl-2015-0014
Pechenick, Eitan Adam, Christopher M. Danforth & Peter Sheridan Dodds. 2015. “Characterizing the Google Books corpus: Strong limits to inferences of socio-cultural and linguistic evolution”. PLoS ONE 10(10): e0137041. doi:10.1371/journal.pone.0137041
Perc, Matjaž. 2012. “Evolution of the most common English words and phrases over the centuries”. Journal of the Royal Society Interface 9(77): 3323–3328. doi:10.1098/rsif.2012.0491
Petersen, Alexander M., Joel N. Tenenbaum, Shlomo Havlin, H. Eugene Stanley & Matjaž Perc. 2012a. “Languages cool as they expand: Allometric scaling and the decreasing need for new words”. Scientific Reports 2: 943. doi:10.1038/srep00943
Petersen, Alexander M., Joel Tenenbaum, Shlomo Havlin & H. Eugene Stanley. 2012b. “Statistical laws governing fluctuations in word use from word birth to word death”. Scientific Reports 2: 313. doi:10.1038/srep00313
Rühlemann, Christoph, Andrej Bagoutdinov & Matthew Brook O’Donnell. 2015. “Modest XPath and XQuery for corpora: Exploiting deep XML annotation”. ICAME Journal 39: 47–84. doi:10.1515/icame-2015-0003
Schäfer, Roland. 2015. “Processing and querying large web corpora with the COW14 architecture”. Proceedings of the 3rd Workshop on Challenges in the Management of Large Corpora (CMLC-3), ed. by Piotr Banski, Hanno Biber, Evelyn Breiteneder, Marc Kupietz, Harald Lüngen & Andreas Witt, 28–34. Mannheim: Institut für Deutsche Sprache. http://nbn-resolving.de/urn:nbn:de:bsz:mh39-38261
Siirtola, Harri, Poika Isokoski, Tanja Säily & Terttu Nevalainen. 2016. “Interactive text visualization with Text Variation Explorer”. Proceedings of the 20th International Conference on Information Visualisation (IV 2016), ed. by Ebad Banissi, 330–335. Los Alamitos, California: IEEE Computer Society. doi:10.1109/IV.2016.57
Silver, Nate. 2015. “Rich data, poor data”. FiveThirtyEight. https://fivethirtyeight.com/features/rich-data-poor-data/
Sinclair, John. 2005. “Corpus and text – basic principles”. Developing Linguistic Corpora: A Guide to Good Practice, ed. by Martin Wynne, 1–16. Oxford: Oxbow Books. http://ota.ox.ac.uk/documents/creating/dlc/chapter1.htm
Singer, Natasha. 2013. “In a scoreboard of words, a cultural guide”. New York Times. http://www.nytimes.com/2013/12/08/technology/in-a-scoreboard-of-words-a-cultural-guide.html
Snijders, Chris, Uwe Matzat & Ulf-Dietrich Reips. 2012. “‘Big data’: Big gaps of knowledge in the field of Internet science”. International Journal of Internet Science 7(1): 1–5. http://www.ijis.net/ijis7_1/ijis7_1_editorial_pre.html
Underwood, Ted. 2011. “The Google dataset as an episode in the history of science”. The Stone and the Shell. https://tedunderwood.com/2011/01/14/the-google-dataset-as-an-episode-in-the-history-of-science/
Wolk, Christoph, Joan Bresnan, Anette Rosenbach & Benedikt Szmrecsanyi. 2013. “Dative and genitive variability in Late Modern English: Exploring cross-constructional variation and change.” Diachronica 30(3): 382–419. doi:10.1075/dia.30.3.04wol
